
ما هو فرط التجهيز Overfitting، في عالم التعلم الآلي (Machine Learning)، يُعد تحقيق التوازن بين دقة النموذج وقدرته على التعميم من أكبر التحديات. يبرز مصطلح “فرط التجهيز” (Overfitting) كواحد من أكثر المشكلات شيوعًا التي تواجه الباحثين والمطورين. يحدث فرط التجهيز عندما يصبح النموذج مُفرطًا في التكيف مع بيانات التدريب، لدرجة أنه يفقد قدرته على التعامل مع بيانات جديدة. في هذا المقال، سنستعرض تعريف فرط التجهيز، علاقته بـ “نقص التجهيز”.
ما هو (Underfitting)، طرق الكشف عنه وتجنبه، مع الإجابة على تساؤلات شائعة، وكيف يمكن لـ “سايبر وان” أن تلعب دورًا في معالجة هذه المشكلة في سياق الأمن السيبراني تابعوا معنا المقال.
ما هو فرط التجهيز Overfitting
فرط التجهيز (Overfitting) هو حالة تحدث في نماذج التعلم الآلي عندما يتعلم النموذج بيانات التدريب بشكل مفرط، بما في ذلك الضوضاء (Noise) والانحرافات العشوائية، بدلاً من التركيز على الأنماط العامة. نتيجة لذلك، يُظهر النموذج أداءً ممتازًا على بيانات التدريب، لكنه يفشل في التنبؤ بدقة عند اختباره على بيانات جديدة أو غير مرئية. بمعنى آخر، يصبح النموذج “مُعقدًا للغاية” وغير قادر على التعميم (Generalization)، وهو الهدف الأساسي للتعلم الآلي.
في علم البيانات يتناسب النموذج الإحصائي تمامًا مع بيانات التدريب الخاصة به. عندما يحدث هذا، فإن الخوارزمية للأسف لا يمكنها الأداء بدقة ضد البيانات غير المرئية، مما يؤدي إلى إفشال الغرض منها. إن تعميم نموذج على بيانات جديدة هو في النهاية ما يسمح لنا باستخدام خوارزميات التعلم الآلي كل يوم لعمل تنبؤات وتصنيف البيانات.
عندما يتم إنشاء خوارزميات التعلم الآلي، فإنها تستفيد من عينة مجموعة بيانات لتدريب النموذج. ومع ذلك، عندما يتدرب النموذج لفترة طويلة جدًا على بيانات العينة أو عندما يكون النموذج شديد التعقيد، يمكن أن يبدأ في التعرف على “الضوضاء” أو المعلومات غير ذات الصلة، ضمن مجموعة البيانات. عندما يحفظ النموذج الضوضاء ويتناسب بشكل وثيق جدًا مع مجموعة التدريب، يصبح النموذج “أكثر من اللازم” ولا يمكنه التعميم جيدًا على البيانات الجديدة. إذا لم يتمكن النموذج من التعميم بشكل جيد على البيانات الجديدة، فلن يكون قادرًا على أداء مهام التصنيف أو التنبؤ التي تم تصميمه من أجلها.
معدلات الخطأ المنخفضة والتباين العالي هي مؤشرات جيدة لفرط التجهيز. ومن أجل منع هذا النوع من السلوك، يتم عادةً وضع جزء من مجموعة بيانات التدريب جانبًا على أنه “مجموعة اختبار” للتحقق من فرط التجهيز. فإذا كانت بيانات التدريب ذات معدل خطأ منخفض وكانت بيانات الاختبار بها معدل خطأ مرتفع، فإنها تشير إلى فرط التجهيز.
Overfitting وUnderfitting والعلاقة بينهما
إذا أدى الإفراط في التدريب أو تعقيد النموذج إلى فرط التجهيز، فإن الاستجابة الوقائية المنطقية ستكون إما إيقاف عملية التدريب مؤقتًا، والمعروف أيضًا باسم “التوقف المبكر” أو تقليل التعقيد في النموذج عن طريق التخلص من المدخلات الأقل صلة. ومع ذلك، إذا توقفت مؤقتًا مبكرًا أو استبعدت عددًا كبيرًا جدًا من الميزات المهمة، فقد تواجه المشكلة المعاكسة، وبدلاً من ذلك، قد لا تلائم نموذجك. يحدث التقليل من الملاءمة عندما لا يتم تدريب النموذج لفترة كافية أو عندما لا تكون متغيرات الإدخال كبيرة بما يكفي لتحديد علاقة ذات مغزى بين متغيرات الإدخال والإخراج.
في كلا السيناريوهين، لا يمكن للنموذج تحديد الاتجاه السائد ضمن مجموعة بيانات التدريب. نتيجة لذلك، يُعمم نقص الملاءمة أيضًا بشكل سيء على البيانات غير المرئية. ومع ذلك، على عكس فرط التجهيز، تعاني النماذج غير المجهزة بدرجة عالية من التحيز وتباينًا أقل في تنبؤاتها. ويوضح هذا مقايضة تباين التحيز، والتي تحدث عندما يتحول نموذج غير ملائم إلى حالة أكثر من اللازم. كما يتعلم النموذج، يقل تحيزه، ولكن يمكن أن يزيد في التباين عندما يصبح مُجهزًا بشكل زائد. عند ملاءمة نموذج ما، يكون الهدف هو العثور على “النقطة المثالية” بين المقاس المناسب والإفراط في التجهيز، بحيث يمكنه إنشاء اتجاه مهيمن وتطبيقه على نطاق واسع على مجموعات البيانات الجديدة، وفيما يلي توضيحات مبسطة حول هذين المفهومين:
- فرط التجهيز (Overfitting): كما ذكرنا، يحدث عندما يكون النموذج شديد التعقيد (مثل وجود عدد كبير من المعاملات أو الطبقات في الشبكات العصبية)، فيتعلم حتى التفاصيل الدقيقة والضوضاء في بيانات التدريب.
- نقص التجهيز (Underfitting): على النقيض، يحدث عندما يكون النموذج بسيطًا للغاية، فلا يتمكن من التقاط الأنماط الأساسية في بيانات التدريب، مما يؤدي إلى أداء ضعيف على كل من بيانات التدريب والاختبار.
- العلاقة بينهما: كلاهما يمثل فشلًا في تحقيق التوازن المثالي بين التعقيد والتبسيط. الهدف هو إيجاد “نقطة التوازن” التي تتجنب كلا المشكلتين، حيث يتعلم النموذج الأنماط المهمة دون التأثر بالضوضاء أو التجاهل الكلي للبيانات.
كيفية الكشف عن فرط التجهيز Overfitting
يكاد يكون من المستحيل الكشف عن فرط التجهيز قبل اختبار البيانات. كما يمكن أن يساعد في معالجة السمة الكامنة في فرط التخصيص، وهو عدم القدرة على تعميم مجموعات البيانات. وبالتالي، يمكن فصل البيانات إلى مجموعات فرعية مختلفة لتسهيل التدريب والاختبار. يتم تقسيم البيانات إلى قسمين رئيسيين، أي مجموعة اختبار ومجموعة تدريب.
تمثل مجموعة التدريب غالبية البيانات المتاحة (حوالي 80٪)، وهي تدرب النموذج. تمثل مجموعة الاختبار جزءًا صغيرًا من مجموعة البيانات (حوالي 20٪)، ويتم استخدامها لاختبار دقة البيانات التي لم تتفاعل معها من قبل. من خلال تقسيم مجموعة البيانات، يمكننا فحص أداء النموذج في كل مجموعة من البيانات لاكتشاف التجاوز عند حدوثه، وكذلك معرفة كيفية عمل عملية التدريب.
يمكن قياس الأداء باستخدام النسبة المئوية للدقة التي لوحظت في كلتا مجموعتي البيانات لاستنتاج وجود فرط في التجهيز. إذا كان أداء النموذج في مجموعة التدريب أفضل من أداءه في مجموعة الاختبار، فهذا يعني أن النموذج من المحتمل أن يكون أكثر من اللازم، ويمكن اكتشاف فرط التجهيز من خلال عدة علامات واضحة، مثل:
- الفرق الكبير في الأداء: إذا كان أداء النموذج ممتازًا على بيانات التدريب (مثل دقة 95%) ولكنه ضعيف على بيانات الاختبار (مثل 60%)، فهذا مؤشر واضح على فرط التجهيز.
- تحليل منحنيات التعلم: عند رسم منحنيات الخطأ (Loss Curves)، نلاحظ أن خطأ التدريب ينخفض باستمرار، بينما يبدأ خطأ الاختبار في الارتفاع بعد نقطة معينة.
- اختبارات التحقق: استخدام مجموعة بيانات تحقق (Validation Set) منفصلة لمراقبة الأداء أثناء التدريب.
 كيفية تجنب حدوث فرط التجهيز Overfitting
كيفية تجنب حدوث فرط التجهيز Overfitting
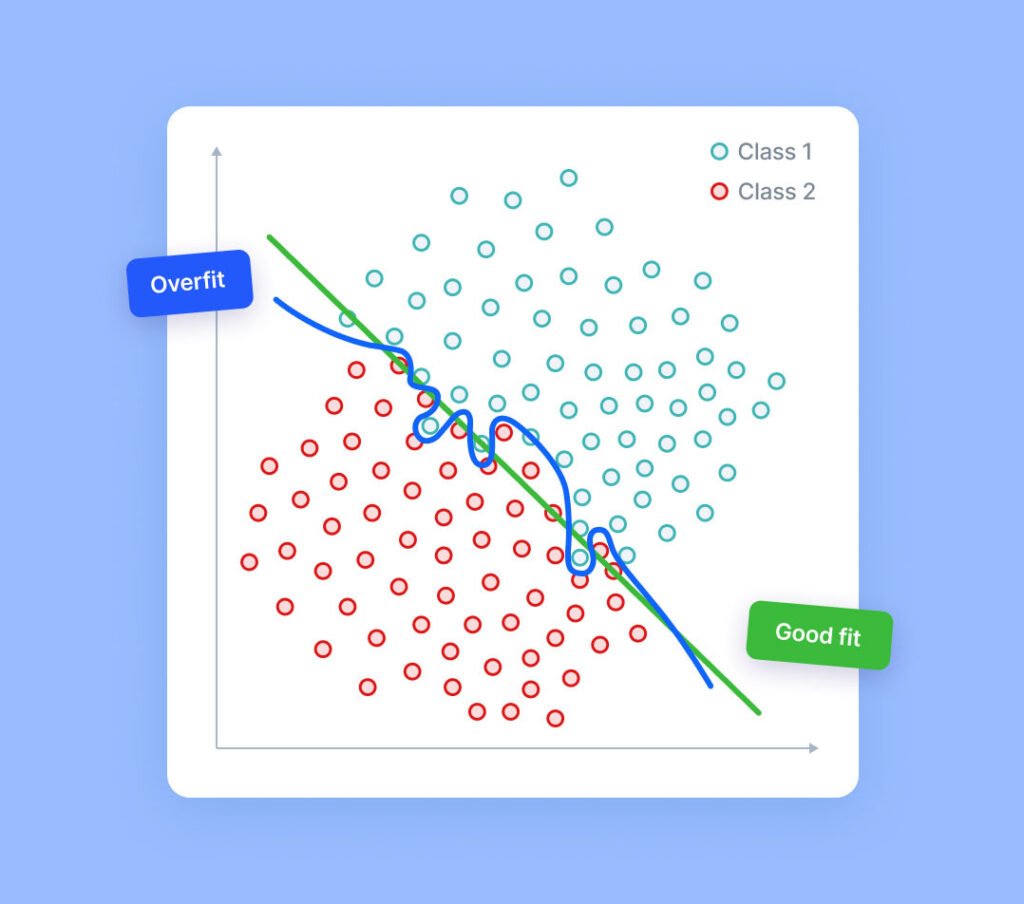 كيفية تجنب حدوث فرط التجهيز Overfitting
كيفية تجنب حدوث فرط التجهيز Overfittingفيما يلي بعض الطرق لمنع فرط التجهيز:
-
التدريب بمزيد من البيانات
إحدى طرق منع فرط التجهيز هي التدريب بمزيد من البيانات. مثل هذا الخيار الذي يجعل من السهل على الخوارزميات اكتشاف الإشارة بشكل أفضل لتقليل الأخطاء. نظرًا لأن المستخدم يغذي المزيد من بيانات التدريب في النموذج، فلن يكون قادرًا على زيادة حجم جميع العينات وسيضطر إلى التعميم للحصول على النتائج.
كما ويجب على المستخدمين جمع المزيد من البيانات باستمرار كطريقة لزيادة دقة النموذج. ومع ذلك، تعتبر هذه الطريقة باهظة الثمن، وبالتالي يجب على المستخدمين التأكد من أن البيانات المستخدمة ملائمة ونظيفة.
-
زيادة البيانات
بديل للتدريب مع المزيد من البيانات هو زيادة البيانات، وهو أقل تكلفة مقارنة بالأول. إذا كنت غير قادر على جمع المزيد من البيانات بشكل مستمر، يمكنك جعل مجموعات البيانات المتاحة تبدو متنوعة.
زيادة البيانات تجعل عينة البيانات تبدو مختلفة قليلاً في كل مرة تتم معالجتها بواسطة النموذج. حيث تجعل العملية كل مجموعة بيانات تبدو فريدة للنموذج وتمنع النموذج من تعلم خصائص مجموعات البيانات.
هناك خيار آخر يعمل بنفس طريقة زيادة البيانات وهو إضافة ضوضاء إلى بيانات الإدخال والإخراج. وتؤدي إضافة الضوضاء إلى الإدخال إلى جعل النموذج مستقرًا، دون التأثير على جودة البيانات والخصوصية، بينما يؤدي إضافة الضوضاء إلى الإخراج إلى جعل البيانات أكثر تنوعًا. ومع ذلك، يجب أن تتم إضافة الضوضاء باعتدال بحيث لا يكون مدى الضوضاء بقدر ما يجعل البيانات غير صحيحة أو مختلفة للغاية.
-
تبسيط البيانات
يمكن أن يحدث التجاوز بسبب تعقيد النموذج، بحيث أنه حتى مع وجود كميات كبيرة من البيانات، لا يزال النموذج قادرًا على تجهيز مجموعة بيانات التدريب. تُستخدم طريقة تبسيط البيانات لتقليل فرط التخصيص عن طريق تقليل تعقيد النموذج لجعله بسيطًا بما يكفي بحيث لا يتسع.
-
التجميع
التجميع هو أسلوب تعلم آلي يعمل من خلال الجمع بين التنبؤات من نموذجين منفصلين أو أكثر، وتشمل طرق التجميع الأكثر شيوعًا التعزيز والتعبئة.
حيث يعمل التعزيز باستخدام نماذج أساسية بسيطة لزيادة تعقيدها الكلي. فهو يدرب عددًا كبيرًا من المتعلمين الضعفاء مرتبة في تسلسل، بحيث يتعلم كل متعلم في التسلسل من أخطاء المتعلم قبله. كما ويجمع التعزيز بين جميع المتعلمين الضعفاء في التسلسل لإخراج متعلم واحد قوي.
بينما طريقة التجميع الأخرى هي التعبئة، وهو عكس التعزيز. حيث تعمل التعبئة عن طريق تدريب عدد كبير من المتعلمين الأقوياء مرتبة في نمط متوازي ثم دمجهم لتحسين توقعاتهم.
نصائح لمنع حدوث فرط التجهيز
هناك استراتيجيات فعالة للحد من فرط التجهيز أقرها الخبراء على شكل نصائح محددة للأفراد والمؤسسات نلخصها في الآتي:
- جمع بيانات أكثر: زيادة حجم بيانات التدريب تقلل من تأثير الضوضاء وتساعد النموذج على التعميم.
- تبسيط النموذج: تقليل عدد المعاملات أو الطبقات في النموذج لتجنب التعقيد الزائد.
- التنظيم (Regularization): استخدام تقنيات مثل L1/L2 Regularization أو Dropout لمعاقبة التعقيد الزائد.
- التحقق المتقاطع (Cross-Validation): تقسيم البيانات إلى عدة مجموعات للتأكد من أداء النموذج على بيانات متنوعة.
- إيقاف التدريب المبكر (Early Stopping): إيقاف التدريب عندما يبدأ أداء التحقق في التدهور.
تساؤلات شائعة حول فرط التجهيز
- ما الفرق بين الضوضاء والأنماط في بيانات التدريب؟
الضوضاء هي التفاصيل العشوائية أو الشوائب غير المهمة (مثل أخطاء في القياس)، بينما الأنماط هي العلاقات المنطقية التي يمكن تعميمها (مثل ارتباط المبيعات بالإعلانات). فرط التجهيز يحدث عندما يتعلم النموذج الضوضاء بدلاً من الأنماط.
- هل فرط التجهيز مشكلة دائمًا؟
ليس بالضرورة، إذا كانت البيانات الجديدة مطابقة تمامًا لبيانات التدريب (وهو أمر نادر)، لكن في معظم الحالات، يقلل من قدرة النموذج على التعامل مع التنوع.
- كيف يؤثر حجم البيانات على فرط التجهيز؟
البيانات الصغيرة تزيد من احتمال فرط التجهيز لأن النموذج قد يحفظها بدلاً من تعلمها، بينما البيانات الكبيرة تمنحه فرصة أكبر للتعرف على الأنماط الحقيقية.
- هل يمكن للتنظيم أن يسبب نقص التجهيز؟
نعم، إذا تم تطبيق التنظيم بشكل مفرط، قد يصبح النموذج بسيطًا للغاية ويفشل في التقاط الأنماط المهمة.
سايبر وان لمكافحة مخاطر الأمن السيبراني
في سياق الأمن السيبراني، تلعب نماذج التعلم الآلي دورًا كبيرًا في كشف التهديدات مثل التصيد الاحتيالي أو اختراق البيانات. لكن فرط التجهيز قد يجعل هذه النماذج غير فعالة عند مواجهة هجمات جديدة غير مطابقة لبيانات التدريب. “سايبر وان” (CyberOne)، كشركة متخصصة في الأمن السيبراني، تقدم حلولًا متقدمة تشمل:
- تصميم نماذج ذكاء اصطناعي متوازنة تتجنب فرط التجهيز باستخدام تقنيات التنظيم والتحقق المتقاطع.
- توفير بيانات تدريب متنوعة ومحدثة لضمان تعميم النماذج على أنواع الهجمات المختلفة.
- دعم المنظمات الأهلية والشركات بأدوات تحليلية تساعد في كشف ومعالجة مشكلات الأداء مثل Overfitting.
من خلال هذه الخدمات، تساهم “سايبر وان” في تعزيز الأمان الرقمي مع ضمان كفاءة النماذج التقنية. ويمكن التواصل معنا عن طريق الأرقام التالية بالاتصال المباشر او على واتس اب:
972533392585+
972505555511+
او من خلال البريد الإلكتروني التالي: info@cyberone.co
فرط التجهيز ليس مجرد مصطلح تقني، بل تحدٍ يعكس الحدود بين الدقة والمرونة في عالم الذكاء الاصطناعي. إنه يذكرنا بأن السعي وراء الكمال في بيئة محددة قد يقودنا إلى الفشل في مواجهة الواقع المتغير. مع تزايد الاعتماد على التعلم الآلي في مجالات مثل الأمن السيبراني، يصبح فهم هذه الظاهرة ومعالجتها أمرًا حاسمًا لضمان أنظمة قوية وموثوقة. من خلال استراتيجيات مثل جمع البيانات المتنوعة، التنظيم الذكي، والاستعانة بحلول مثل “سايبر وان”، يمكننا تحويل هذا التحدي إلى فرصة للابتكار. في النهاية، الأمر لا يتعلق فقط بتجنب فرط التجهيز، بل ببناء نماذج تتكيف مع المستقبل، تحمي بياناتنا، وتدعم رؤية عالم رقمي أكثر أمانًا واستدامة.
جميع الحقوق محفوظة لشركة سايبر وان المختصة في الامن السيبراني والجرائم الإلكترونية
لا يحق لكم نقل او اقتباس اي شيء بدون موافقه الشركة قد يعاقب عليها القانون.
للتواصل info@cyberone.co
00972533392585